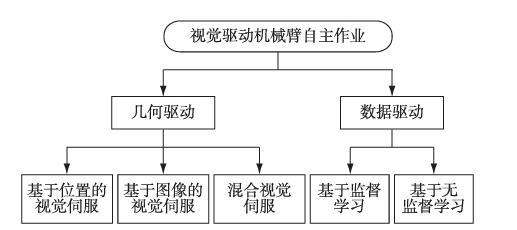
核心技术
Core technology
Autonomous operation technology of vision driven robot arm
Vision is one of the important ways to perceive the surrounding environment. The autonomous operation of vision controlled robotic arms has been proposed for a long time, and its development is mainly from the analysis-based method to the data-driven method. With the continuous development of imaging system and computer technology, visual servo control has become one of the effective control methods, which realizes closed-loop control through image feedback information. For grasping operations in simple scenarios, visual servo control has achieved remarkable results, such as in sorting, handling and other pipelining operations. However, it is difficult for visual servo control to cope with complex scenes and autonomous operations in unstructured environments, such as grasping targets in complex dynamic scenes under water. In recent years, with the improvement of hardware level, especially the development of high-speed parallel modules such as Gpus, and the rapid development of deep learning in the field of machine vision, data-driven approaches have received widespread attention. Data-driven methods include supervised learning and unsupervised learning. The method of supervised learning focuses on the perception of the environment, generally through object detection or semantic segmentation technology to get the best grasp posture, and then use the inverse kinematic transformation method to control the robot arm grasp. However, this method generally adopts open-loop control, which is difficult to meet the needs of autonomous operation in dynamic changing scenarios. In the method of unsupervised learning, the robot arm itself interacts with the environment, learns through experience, and trains a human-like brain for the robot arm to perceive the external environment and decide the most appropriate action to complete the given task. This kind of methods generally carry out sequential inference for grasping tasks, and show great potential in complex dynamic scenes.
Autonomous operation of manipulator based on geometric drive
Geometric drive is to plan the most reasonable grasping posture through the analysis of geometry and kinematics. This kind of method mainly deals with the grasp of known objects in the database, and the model of the object to be grasped needs to be stored in the database in advance, which is usually combined with traditional visual servo. The concept of visual servo was proposed in 1979, referring to the use of computer vision to control the movement of the robot, is a closed-loop control mode. It continuously collects image information through the sensor as a feedback signal to further control or self-adaptive adjustment of the machine. In the tutorial of visual servo written by Hutchinson et al in 1996, visual servo is divided into position-based visual servo and image-based visual servo. In 1999,Malis et al. proposed the concept of hybrid visual servo.
The feedback signal of position-based visual servo (PBVS) control method is given in the form of Cartesian coordinate system, and the input error signal is the difference between the expected pose and the current pose, as shown in the figure. Firstly, the image information collected by the sensor is processed, the feature points are extracted, and the difference between the desired pose of the target and the pose of the end-effector of the robot arm is obtained according to the camera calibration. Then the joint rotation Angle is solved by inverse kinematics to realize the control of the robot arm. Its core task is to realize the pose estimation of the object according to the extracted object features. There are many methods for pose estimation, such as analytic method, iterative method, filter based method and so on. With the emergence of high-performance RGB·D cameras such as Intel RealSense and Kinect, more and more people predict the target pose through depth cameras. Li Shuchun et al used Kinect to obtain the target point cloud for unstructured environments, and then estimated the target pose by extracting fast point feature histogram descriptors combined with singular value decomposition algorithm.
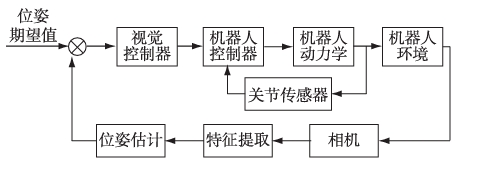
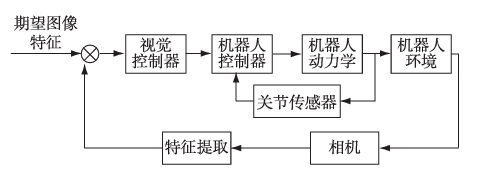
Image-based visual servo (IBVS) implements closed-loop control in the image space, as shown in the figure. The feedback signal of the control method is the difference between the expected value of the image feature and the current value. The measured image signal is compared with the image signal of the target position, and the error of the obtained image is used for control. This method extracts the feature points in the image, but does not need to perform pose estimation calculation. Instead, a dynamic control model is established by combining the motion of the robot and the motion of the feature points in the image through the Jacobian matrix, and then the control instructions of the computer are obtained according to the dynamic control model. Its core is to find the stable feature points and establish the nonlinear mapping relationship between the visual space and the robot motion space, such as the common geometric features such as points, lines, or features based on image moments. In addition, there are also motion models that use the whole image as the feature to establish the objective function to describe the feature of the image. For example, based on the feature of the point, let the spatial position of the feature point relative to the camera coordinate system be marked as (x, y, z), and the pixel position mapped to the imaging plane be marked as (X, Y, 1), where X = x/z, Y = y/z. It can be seen that the camera motion causes a change in the target point (x, y, z), which causes a change in (X, Y, 1). The Jacobian matrix LP of planar pixel features describes the transformation relationship between camera motion rate and pixel coordinate change rate. Where, Vcam = [Vx, Vy, Vz] T, Wcam = [Wx, Wy, Wz] T are the linear velocity vector and angular velocity vector of the camera respectively. (2) In image-based visual servo system, the model mainly refers to the image Jacobian matrix and the kinematics model of the robot arm. How to quickly obtain the image Jacobian matrix is a key problem.
Hybrid visual servo (HVS) includes Cartesian coordinate space closed-loop control and image space closed-loop control, also known as 2.5D visual servo. The feedback signal of the control method is the homography matrix between the desired image and the current image, and the attitude control component is obtained by the decomposition of the homography matrix. This method combines the advantages of PBVS and IBVS, and enhances the robustness of the algorithm, but its computation is large and its real-time performance is poor. Some researchers realize the control of the robot arm by switching between different visual servo control modes. For example, in 2020, Haviland et al. proposed a method of switching between PBVS and IBVS to grasp non-stationary targets. First, PBVS visual servo is used to approach the target from a distance, and then IBVS is switched to continue to approach the target. The visual servo strategy from coarse to fine is realized.
Data-driven control based
With the rapid development of deep learning, researchers have applied this field to the autonomous operation of vision-driven robotic arms, forming data-driven control methods. Data-driven control methods include supervised learning methods and unsupervised learning methods. The research of autonomous grasping of robotic arm based on supervised learning mainly focuses on the estimation of grasping pose. The general process of autonomous control based on deep learning is consistent with that of geometry-driven control. Compared with geometry-driven method, data-driven based on deep learning is more robust in chaotic and obscured job scenes with the help of the powerful feature extraction architecture of neural network, and can realize the grasp of known, similar and unknown objects.
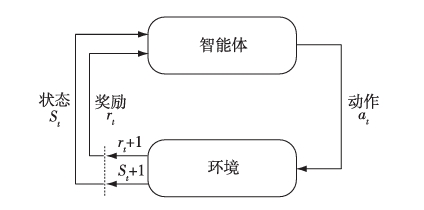
Reinforcement learning is also a field of machine learning, which is a method of unsupervised learning. As shown in the figure, reinforcement learning is a machine learning method in which agents interact with the environment, perceive the external environment, make decisions according to the perceived state, and then get the evaluation of the feedback from the environment, and constantly adjust the strategy according to the information obtained from the interaction with the environment to obtain the maximum reward. Because of its autonomous learning ability and the ability to simulate the learning process of humans and animals, it is considered to be an effective machine learning method to solve control and decision problems. The main algorithms of reinforcement learning include value-based method, policy-based method and the combination of the two methods. Value-based methods estimate the expected return of a certain state or a certain state-action pair and get the best strategy by maximizing this expected return, which is often used to deal with discrete action Spaces. Value-based methods include Q-learning, Sarsa, etc. In order to handle the continuous action space, the method based on Policy search adopts a parameterized strategy and optimizes this parameterized strategy to obtain the optimal strategy, such as the method of Policy gradient. However, the policy-based search method has the problem of high variance, so the value-based thought is combined with the policy-based thought, that is, the actor-critic method, such as DDPG.
Robot arm control based on supervised learning
The study of autonomous operation of robotic arm based on supervised learning separates external perception from motor control. Through the deep neural network to realize the perception of the outside world, get the grasp pose, and then control the robot arm through the inverse kinematic transformation. The research of manipulator control based on deep learning mainly focuses on grasping detection. According to the different grasping environment, it is mainly divided into 2D plane grasping and 6Degree of freedom (6DOF) grasping.
Robotic arm control based on unsupervised learning
The unsupervised reinforcement learning method enables the robotic arm to learn independently in the process of interacting with the environment without modeling the environment, so it has been widely concerned. At present, the research of using reinforcement learning algorithm to control the autonomous operation of robot arm is mainly in the experimental stage. In recent years, a variety of related technologies and algorithms have been proposed, and new research results have emerged. In many training environments of robotic arms, pose parameters of robotic arms or target pose parameters are directly used as reinforcement learning state input to realize control of robotic arms. This method has a fast training speed and good effect, but it is unrealistic to directly use the pose parameters of robotic arms or target pose parameters for training in actual use, and image input is a more general and feasible way.